

Entre nouveaux algorithmes et avancées informatiques, les machines peuvent désormais apprendre des modèles de plus en plus complexes. Ils en viennent à générer des données synthétiques de haute qualité telles que des images photoréalistes et même des CV d'humains fictifs.
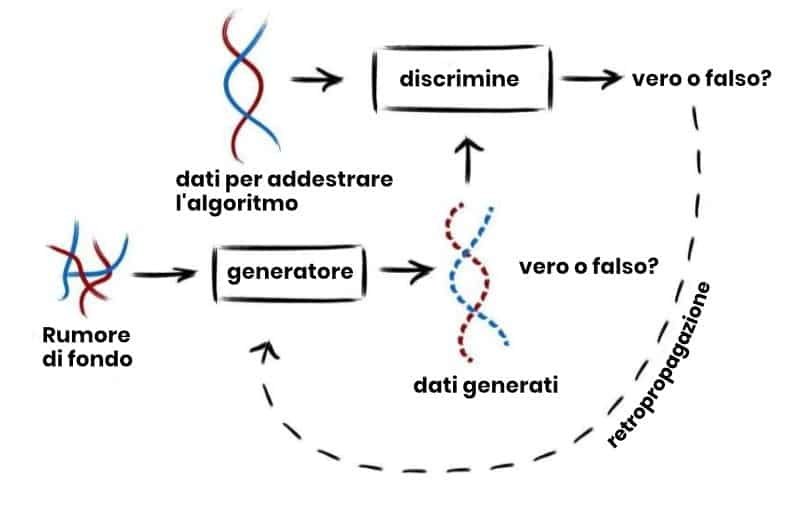
maintenant une étude publiée dans la revue internationale PLoS Genetics montre l’utilisation avancée de l’apprentissage automatique sur les données biométriques. À partir des biobanques existantes, le système génère des blocs entiers de génome humain qui n’appartiennent pas à de vrais humains mais présentent les caractéristiques d’un véritable génome.
Contourner le problème de confidentialité
« Les bases de données génomiques existantes constituent une ressource inestimable pour recherche biomédicale," Il dit Bourak Yelmen, premier auteur de l'étude et chercheur junior en génétique moderne des populations à l'Université de Tartu. « Le problème est qu’ils ne sont pas accessibles au public ni protégés par des procédures d’application longues et fastidieuses en raison de préoccupations éthiques valables. Cela crée un obstacle scientifique majeur pour les chercheurs. Un génome généré automatiquement, un « génome artificiel », peut nous aider à surmonter le problème dans un cadre éthique sûr. »
:format(jpg):extract_cover()/https%3A%2F%2Fscx1.b-cdn.net%2Fcsz%2Fnews%2F800a%2F2021%2F13-machinelearn.jpg)
L’équipe multidisciplinaire a réalisé plusieurs analyses pour évaluer la qualité du génome généré par l’apprentissage automatique par rapport au génome réel. « Remarquablement, ce génome imite les complexités que nous pouvons observer au sein de populations humaines réelles et, pour la plupart des propriétés, ils sont indiscernables des autres génomes de la biobanque utilisée pour entraîner notre algorithme. À un détail près : ils n’appartiennent à aucun donneur de gènes », a précisé le dr. Luca Pagani, l'un des principaux auteurs de l'étude et collègue Mobilitas Pluss.
Un génome généré automatiquement, un « génome artificiel », peut nous aider à surmonter le problème dans un cadre éthique sûr.
Bourak Yelmen
Le génome est-il vraiment original ou une copie « crachée » ?
L’étude consiste également à évaluer la proximité du génome artificiel avec le génome réel pour vérifier si la confidentialité des échantillons originaux est préservée. « Même si détecter des fuites de données sur des milliers de génomes peut sembler comme chercher une aiguille dans une botte de foin, la combinaison de plusieurs mesures statistiques nous permet de vérifier soigneusement tous les modèles. Il est intéressant de noter que l’exploration détaillée de modèles de dispersion complexes conduit à son tour à d’autres améliorations dans l’évaluation de GAN et alimentera le domaine de l’apprentissage automatique. Le docteur le dit Flora Geai, coordinateur d'étude et chercheur au CNRS, Centre National de la Recherche Scientifique).
Dans l'ensemble, les approches d'apprentissage automatique déjà proposées visages, biographies et beaucoup d'autres fonctionnalités à une poignée d'êtres humains imaginaires. Nous en savons désormais davantage sur leur biologie. Ces humains fictifs aux génomes réalistes pourraient servir de banc expérimental à la place de génomes réels qui ne sont pas accessibles au public.

