
L’ère des assistants IA est de plus en plus proche : l’interface avec des visages et des avatars numériques devient rapidement partie intégrante de notre vie quotidienne. Jusqu’où ces visages numériques peuvent-ils aller pour reproduire le réalisme d’une personne réelle ? Très loin, à en juger par VASA-1, le modèle innovant d'intelligence artificielle qui vient d'être développé par Microsoft Research. Ici vous pouvez trouver le document.
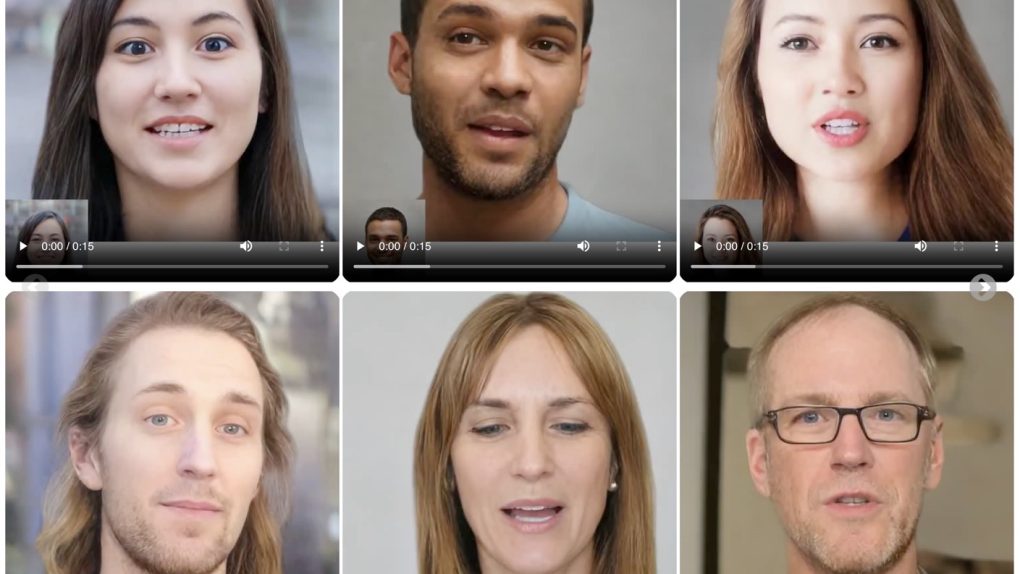
VASA-1 peut générer des vidéos ultra-réalistes de visages parlants en temps réel à partir d'une seule image et d'un fichier audio. Il repoussera les limites de ce qui est possible en matière de création d'avatars numériques, avec des applications allant des appels vidéo au contenu de divertissement en passant par l'amélioration de l'accessibilité pour les personnes malentendantes.

VASA-1, un réalisme sans précédent
Ce qui rend VASA-1 véritablement révolutionnaire, c'est le niveau de réalisme qu'il est capable d'atteindre. Les vidéos générées par ce modèle d’IA sont pratiquement impossibles à distinguer de celles de personnes réelles.
Ceci est rendu possible par une série de fonctionnalités innovantes. Tout d'abord, VASA-1 offre une synchronisation parfaite entre les mouvements des lèvres et l'audio. Quelle que soit la langue ou la présence de bruit de fond, les lèvres de l'avatar bougent en parfaite synchronisation avec les mots prononcés, créant un effet d'un réalisme surprenant.
De plus, VASA-1 est capable de capturer et de reproduire un large éventail d'expressions faciales, des nuances les plus subtiles aux émotions les plus marquées. Cela ajoute un niveau supplémentaire de profondeur et d'authenticité aux avatars générés et au "personnes numériques" .
Enfin, les mouvements de tête sont générés de manière naturelle et fluide, contribuant à l'impression d'être devant une personne réelle et non devant une image statique.

Génération en temps réel et haute qualité
Je trouve impressionnante la capacité du VASA-1 à générer ces vidéos ultra-réalistes en temps réel. Il a actuellement une résolution de 512x512 pixels et une vitesse allant jusqu'à 40 images par seconde, mais ce sont des avatars parlant en direct, sans retards ni interruptions.
Cela ouvre la voie à un certain nombre d’applications innovantes. Par exemple, VASA-1 pourrait être utilisé pour créer des avatars personnalisés pour les appels vidéo, rendant ainsi les interactions virtuelles plus engageantes et réalistes. Il pourrait également être utilisé pour générer des personnages interactifs dans des jeux vidéo ou pour créer du contenu vidéo éducatif et divertissant avec des présentateurs virtuels.
Vers une plus grande accessibilité
L’une des applications potentielles les plus intéressantes de VASA-1 concerne l’accessibilité. En générant des vidéos de visages parlants à partir d’un fichier audio, ce modèle d’IA pourrait être utilisé pour créer des versions accessibles de contenu vidéo pour les personnes malentendantes.
Imaginez pouvoir regarder un discours ou une conférence avec un avatar de locuteur articulant clairement les mots en synchronisation avec l'audio. Cela pourrait rendre le contenu beaucoup plus utilisable pour les personnes malentendantes, ouvrant ainsi de nouvelles possibilités d'apprentissage et de participation.
L'avenir de VASA-1 et la communication virtuelle
Les chercheurs de Microsoft ne sont pas satisfaits et travaillent déjà pour améliorer encore les performances du VASA-1. À l’avenir, nous pouvons nous attendre à des avatars parlants de qualité encore supérieure, encore plus fluides et avec des résolutions plus élevées. Sans parler des horaires et des coûts des films et animations : ils seront totalement modifiés.
Ceux d'entre vous se souviennent de la série télévisée pionnière "Max Headroom« ? Là, un vrai journaliste a été « ressuscité » sous la forme d'un avatar virtuel. Une série visionnaire, il y a 30 ans, qui sera bientôt totalement dépassée par les faits. À mesure que VASA-1 et les technologies similaires progressent, la frontière entre communication virtuelle et interaction en face à face peut devenir de plus en plus floue.
Bien entendu, cette perspective soulève également des questions éthiques et sociales. Il sera important d’élaborer des lignes directrices et des réglementations pour garantir une utilisation responsable et transparente de ces technologies, en protégeant la vie privée et en prévenant d’éventuels abus tels que la création de deepfakes.
Cela dit, les avantages potentiels de modèles comme le VASA-1 sont énormes.
D’une communication plus engageante à un apprentissage amélioré, d’un divertissement plus interactif à une plus grande accessibilité, les applications sont vastes et prometteuses.
VASA-1 nous offre un aperçu fascinant d'un avenir dans lequel la communication virtuelle sera de plus en plus impossible à distinguer de la communication en face à face. C'est un avenir où les avatars ultra-réalistes pourront transmettre non seulement des mots, mais aussi des émotions, des expressions et une présence. Un avenir où la distance physique sera moins un obstacle et où l’accessibilité aux contenus sera grandement améliorée.
Je suis vraiment curieux de voir comment VASA-1 (et ses successeurs) transformeront notre façon de communiquer, d'apprendre et de nous divertir dans les années à venir. La révolution du visage numérique vient de commencer et l’avenir semble plus réaliste que jamais.

